Co mają ze sobą wspólnego: napis na ścianie, wiersz Leśmiana i sprawdzian z biologii? Czy to się w jakiś sposób łączy z genetyką molekularną? Jak rozróżnić kod genetyczny i informację genetyczną? Już wszystko wyjaśniam.
Muszę przyznać, do napisania tego posta zainspirowało mnie National Geographic, które postując informację o pewnym eksperymencie chińskich naukowców, wykazało się gigantyczną ignorancją w kwestii genetyki molekularnej (więcej pisałam o tym tutaj). Jeśli światowe wydawnictwa nie rozróżniają kodu genetycznego od informacji genetycznej, to dlaczego miałoby to być proste dla maturzystów? Więc wyjaśnimy sobie parę kwestii raz a porządnie.
Czym jest informacja genetyczna?

Wyobraźmy sobie napis na ścianie, wiersz i fragment sprawdzianu z biologii. Teoretycznie te 3 rzeczy nie mają ze sobą wiele wspólnego, ale zauważcie jedno: wszystkie niosą ze sobą jakąś informację (są informacją) i wszystkie zostały zaszyfrowane za pomocą jednego kodu (alfabet łaciński). Czyli za pomocą kodu – możemy zapisać dowolną informację, ogranicza nas tylko wyobraźnia lub ambicja odnośnie twórczości. Tak samo z informacją genetyczną: to jest informacja o budowie konkretnych białek. To, jakie to będą białka, ile ich będzie i jak złożone struktury będą tworzyć zależy już od organizmu, który będą budować. Ale wszystkie będą zapisane w ten sam sposób: przy użyciu kodu genetycznego.
Czym jest kod genetyczny?
To prowadzi nas do prostej konkluzji: kod genetyczny jest rodzajem szyfru, który służy zapisaniu danej informacji (w tym przypadku informacji o budowie białka, która zapisana jest w kwasach nukleinowych). Może warto sobie uświadomić, jak często korzystamy z przeróżnych kodów: przykładowo, pisząc ten tekst, posługuję się kodem (alfabet łaciński) – możecie odkodować informacje, jakie staram się przekazać, ponieważ nauczyliście się tego kodu i umiecie rozszyfrować to, co piszę. Mamy też inne kody: alfabet Braille’a, alfabet Morse’a, kody kreskowe na opakowaniach prawie wszystkiego, co można kupić w sklepie, lub nuty, które są graficznym zapisem dźwięków.
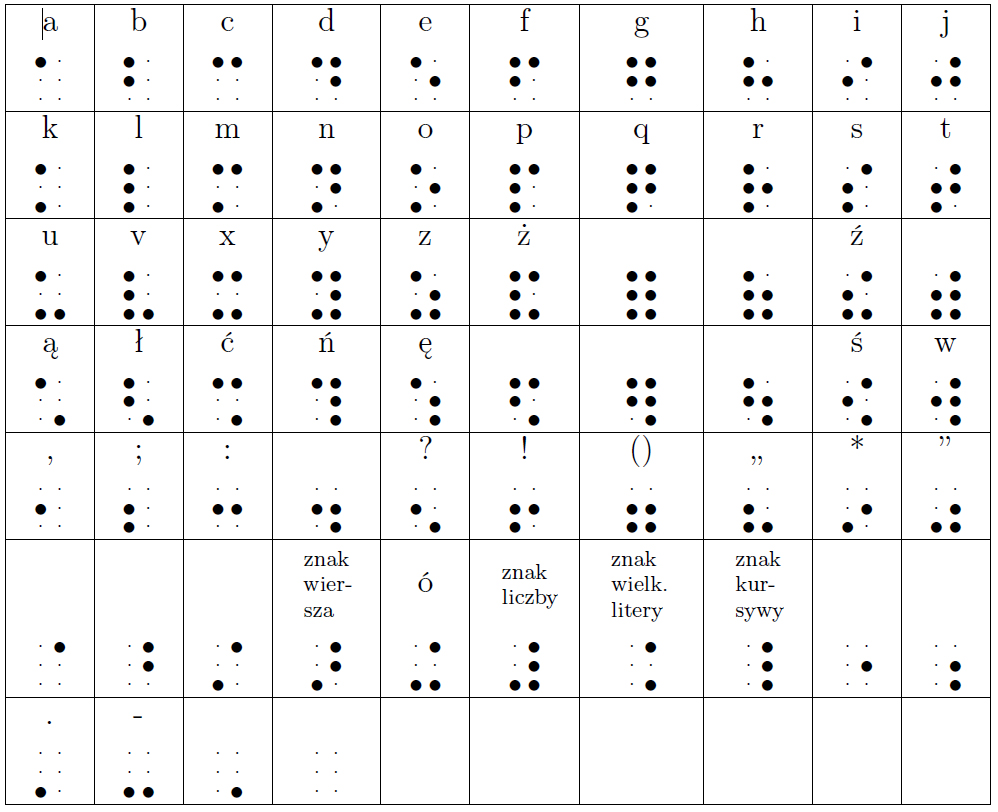


Trzy rodzaje kodu: alfabet Braille’a, alfabet Morse’a i zapis nutowy.
Kod genetyczny a informacja genetyczna
Warto pamiętać o bardzo istotnej kwestii: kod genetyczny jest stały. Ludzie, to jest SPOSÓB ZAPISU. On nie może ulegać zmianom. Co innego informacja genetyczna (czyli nasze geny): ona ulega modyfikacjom, na skutek działań inżynierii genetycznej lub w bardziej naturalnej formie – na skutek mutacji. Wtedy najczęściej dochodzi do zmian w budowie białka (chociaż nie zawsze).
Powiedzmy, że zapisuję zdanie: Lubię kiwi.
To zdanie jest informacją. Ale mogę tę informację zmienić, na : Nie lubię kiwi.
Zmieniam informację, ale nie zmienia się kod, jakim się posługuję, bo dalej działam w obrębie łacińskiego alfabetu. Czyli SPOSÓB ZAPISU SIĘ NIE ZMIENIA. Tak samo w wyniku mutacji zmieni się informacja genetyczna (budowa białka), ale nie kod – bo sposób zapisu pozostaje taki sam.
Jaki on jest? Cechy kodu genetycznego
Wśród różnych cech kodu genetycznego (z których chyba zrobię Wam ściągę do pobrania) jest m.in. uniwersalność. Co to znaczy? To znaczy, że ten sam sposób zapisu informacji występuje u większości organizmów. Kod genetyczny jest bardziej uniwersalny niż alfabet łaciński, bo według Wikipedii alfabetem posługuje się około 35% ludności świata. A 100% ludzi na Ziemi ma ten sam kod genetyczny. Mało tego, nasz kod genetyczny jest taki sam jak kod ryb, owadów, bakterii czy nawet wirusów (a ich najczęściej nawet nie zalicza się do organizmów żywych). Różnimy się nie sposobem zapisu, a tym, jakie informacje w nas zapisano.

Często nie uświadamiamy sobie, jakie to ma znaczenie. Po pierwsze, uniwersalność kodu genetycznego jest jednym z pośrednich dowodów ewolucji. Czyli informacja o budowie organizmów ewoluowała, a sposób zapisu (kod) pozostał taki sam. Druga kwestia: dzięki tej uniwersalności jesteśmy w stanie tworzyć organizmy modyfikowane genetycznie. Czyli dzięki temu gen ludzkiej insuliny (nasza informacja genetyczna) może zostać wszczepiony do bakterii i bakteria wyprodukuje ludzkie białko (czyli rozszyfruje informację zapisaną kodem, który zna i rozumie). To jest oczywiście spore uproszczenie, bo bakteriom trzeba wszczepiać cDNA a nie DNA, ze względu na nieciągłość naszych genów – ale ogólny sens procesu zostaje zachowany 🙂
Zrozumienie molekularnych procesów bywa trudne – w końcu to dość abstrakcyjne pojęcia, których raczej nie obserwujemy na co dzień, gołym okiem. Są oderwane od naszej rzeczywistości. Dlatego warto szukać analogii do znanych nam, oczywistych pojęć – wtedy zrozumienie przychodzi łatwiej i mniej boleśnie 😉 .
Jeśli masz trudność z zadaniami typu: „tu jest sekwencja nukleotydów, podaj sekwencje aminokwasów” albo nie rozróżniasz nici kodującej od matrycowej i mylisz je z mRNA, to mam coś, co może Ci pomóc: krótka lekcja, która ułoży wszystko w głowie + fiszki gratis!



